











Computing with Strings
Sue Evans & Travis Mayberry
Adapted from the CS1 Course at Swarthmore College by Lisa Meeden
Hit the space bar for next slide
Sue Evans & Travis Mayberry
Adapted from the CS1 Course at Swarthmore College by Lisa Meeden
Hit the space bar for next slide
Just like range(x) returns a sequence of numbers, strings are sequences of characters
>>> for ch in 'hello': ... print ch ... h e l l o >>>
Unlike other languages, strings in Python are denoted using either single or double quotes
>>> myString = "Goodbye" >>> myString 'Goodbye'
This allows us to easily have quoted text within a string.
>>> fact = '"The Cat In the Hat" was written by Dr. Suess.' >>> print fact "The Cat In the Hat" was written by Dr. Suess. >>>
| Operation | Python Operator |
|---|---|
| Concatenation | |
| Repetition | |
| Indexing | |
| Slicing |
Examples using these operators:
>>> 'snow' + 'ball' 'snowball' >>> 'hello' * 3 'hellohellohello'
Oops. Let's see if we can do better ...
>>> 'hello ' * 3 + '!' 'hello hello hello !'
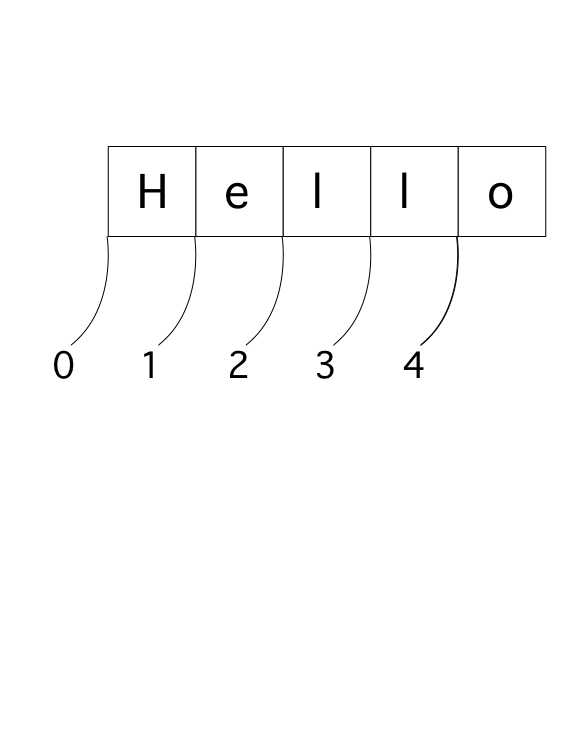
Notice in the next example that indexing begins with 0
>>> 'hello'[4] 'o'
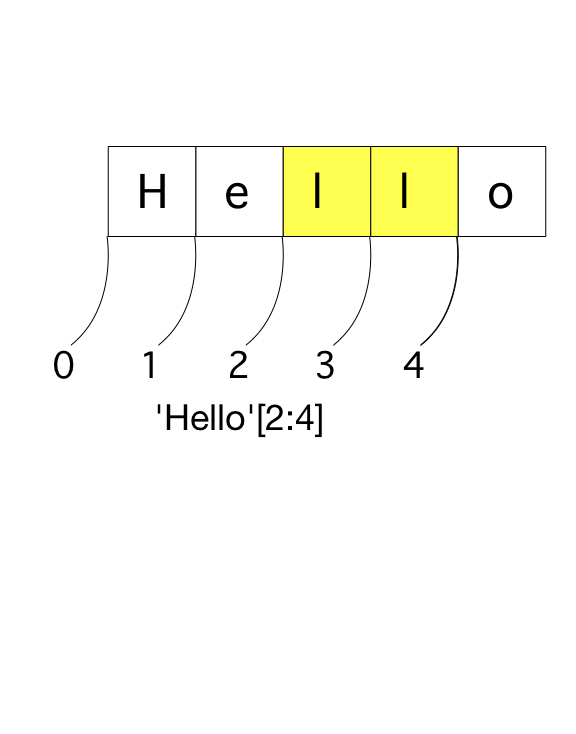
Also notice, when slicing, that the character at the first index is included in the slice and all characters from that position up to one less than the second index shown.
>>> 'hello'[1:4] 'ell'
Python also allows use of negative indexes.
An index of -1 is equivalent to the largest index of the string.
>>> 'sample'[-1]
'e'
>>> len('sample')
6
>>> 'sample'[5]
'e'
>>> 'sample'[-3]
'p'
In order to use the string library, you have to import it :
import string
| Function | Purpose |
|---|---|
| string.capitalize(s) | Returns s with only the first letter capitalized |
| string.capwords(s) | Returns s with the first letter of each word capitalized |
| string.count(s, sub) | Returns the number of times sub occurs in s |
| string.find(s, sub) | Finds the first occurrence of sub in s and returns its position or -1 if it is not found |
| string.join(list) | Concatenates a list of strings together to make one string |
| string.upper(s) | Returns a copy of s in all capital letters |
| string.lower(s) | Returns a copy of s in all lower case letters |
| string.split(s, c) | Returns a list of strings made by splitting s on each occurence of c |
| string.strip(s) | Removes all whitespace from the beginning and end of s |
>>> import string
>>> string.lower("Hello World")
'hello world'
>>> string.upper("Hello World")
'HELLO WORLD'
>>> string.count("isn't this it", "is")
2
>>> string.strip(" Hello World \n")
'Hello World'
>>> string.strip(" \n \n \n \t \n ")
''
>>> string.split("Hello World from U M B C")
['Hello', 'World', 'from', 'U', 'M', 'B', 'C']
>>> "Hello World from U M B C".split() ['Hello', 'World', 'from', 'U', 'M', 'B', 'C'] >>>
As binary, of course. Everything is stored in binary!
The technique used for characters is that each character is assigned a number (an integer), and that number is stored in binary.
Recall that an integer is 4 bytes big, with 8 bits/byte, that means an integer needs 32 bits of memory. That allows us to count up to 2147483647. But do we really need all that space to represent a character ?
If you think about the English language and everything that's necessary to communicate, there are very few individual characters :
| Type of character | Number |
|---|---|
This means that in order to assign a number to each character, we only
need to count to 95.
How many bits does that take ?
| value | bits |
|---|---|
So by storing characters in just one byte (8 bits), the amount of memory
needed for each character is only 1/4 of the amount of space needed by an
int. This is a tremendous amount of saved space for storing text.
So all characters are only one byte big.
Trivia Question: How big is a nibble ?
American Standard Code for Information Interchange or ASCII was derived from telegraphic codes. Work began on ASCII in 1960 with the first version published in 1963. There was a major revision in 1967. The current version became available in 1986.
There are 128 characters defined in ASCII. 33 are nonprinting control characters that control communication devices and printers, like line feed or form feed. 32 (0 - 31) control characters are at the beginning of the chart and one at the end, delete (127). Many of the control characters are obsolete. The values 32 - 126 are the definitions of the printable characters made up of numbers, letters, punctuation, whitespace and symbols.
Just as integers can be cast into floats, characters can be cast into their ASCII values, and from ASCII values back into their characters. Numbers have ASCII values from 48-57, while uppercase letters are 65-90 and lowercase letters are 97-122. Here is a full ASCII table.
>>> chr(104)
'h'
>>> ord('h')
104
Let's print out an ASCII chart for just the printable characters.
How would we do that ?
>>> for num in range(32, 127):
... print num, '=', chr(num)
...
32 =
33 = !
34 = "
35 = #
36 = $
37 = %
38 = &
39 = '
40 = (
41 = )
42 = *
43 = +
44 = ,
45 = -
46 = .
47 = /
48 = 0
49 = 1
50 = 2
51 = 3
52 = 4
53 = 5
54 = 6
55 = 7
56 = 8
57 = 9
58 = :
59 = ;
60 = <
61 = =
62 = >
63 = ?
64 = @
65 = A
66 = B
67 = C
68 = D
69 = E
70 = F
71 = G
72 = H
73 = I
74 = J
75 = K
76 = L
77 = M
78 = N
79 = O
80 = P
81 = Q
82 = R
83 = S
84 = T
85 = U
86 = V
87 = W
88 = X
89 = Y
90 = Z
91 = [
92 = \
93 = ]
94 = ^
95 = _
96 = `
97 = a
98 = b
99 = c
100 = d
101 = e
102 = f
103 = g
104 = h
105 = i
106 = j
107 = k
108 = l
109 = m
110 = n
111 = o
112 = p
113 = q
114 = r
115 = s
116 = t
117 = u
118 = v
119 = w
120 = x
121 = y
122 = z
123 = {
124 = |
125 = }
126 = ~
>>>
>>> for num in range(32, 127, 6):
... print num, '=', chr(num),
... print num + 1, '=', chr(num + 1),
... print num + 2, '=', chr(num + 2),
... print num + 3, '=', chr(num + 3),
... print num + 4, '=', chr(num + 4),
... print num + 5, '=', chr(num + 5)
...
32 = 33 = ! 34 = " 35 = # 36 = $ 37 = %
38 = & 39 = ' 40 = ( 41 = ) 42 = * 43 = +
44 = , 45 = - 46 = . 47 = / 48 = 0 49 = 1
50 = 2 51 = 3 52 = 4 53 = 5 54 = 6 55 = 7
56 = 8 57 = 9 58 = : 59 = ; 60 = < 61 = =
62 = > 63 = ? 64 = @ 65 = A 66 = B 67 = C
68 = D 69 = E 70 = F 71 = G 72 = H 73 = I
74 = J 75 = K 76 = L 77 = M 78 = N 79 = O
80 = P 81 = Q 82 = R 83 = S 84 = T 85 = U
86 = V 87 = W 88 = X 89 = Y 90 = Z 91 = [
92 = \ 93 = ] 94 = ^ 95 = _ 96 = ` 97 = a
98 = b 99 = c 100 = d 101 = e 102 = f 103 = g
104 = h 105 = i 106 = j 107 = k 108 = l 109 = m
110 = n 111 = o 112 = p 113 = q 114 = r 115 = s
116 = t 117 = u 118 = v 119 = w 120 = x 121 = y
122 = z 123 = { 124 = | 125 = } 126 = ~ 127 =
>>>
>>> for num in range(32, 127, 6):
... print "%5d = %c" % (num, chr(num)),
... print "%5d = %c" % (num + 1, chr(num + 1)),
... print "%5d = %c" % (num + 2, chr(num + 2)),
... print "%5d = %c" % (num + 3, chr(num + 3)),
... print "%5d = %c" % (num + 4, chr(num + 4)),
... print "%5d = %c" % (num + 5, chr(num + 5))
...
32 = 33 = ! 34 = " 35 = # 36 = $ 37 = %
38 = & 39 = ' 40 = ( 41 = ) 42 = * 43 = +
44 = , 45 = - 46 = . 47 = / 48 = 0 49 = 1
50 = 2 51 = 3 52 = 4 53 = 5 54 = 6 55 = 7
56 = 8 57 = 9 58 = : 59 = ; 60 = < 61 = =
62 = > 63 = ? 64 = @ 65 = A 66 = B 67 = C
68 = D 69 = E 70 = F 71 = G 72 = H 73 = I
74 = J 75 = K 76 = L 77 = M 78 = N 79 = O
80 = P 81 = Q 82 = R 83 = S 84 = T 85 = U
86 = V 87 = W 88 = X 89 = Y 90 = Z 91 = [
92 = \ 93 = ] 94 = ^ 95 = _ 96 = ` 97 = a
98 = b 99 = c 100 = d 101 = e 102 = f 103 = g
104 = h 105 = i 106 = j 107 = k 108 = l 109 = m
110 = n 111 = o 112 = p 113 = q 114 = r 115 = s
116 = t 117 = u 118 = v 119 = w 120 = x 121 = y
122 = z 123 = { 124 = | 125 = } 126 = ~ 127 =
>>>
What would you expect the following to do?
x = input() #User types: hello world print x
Output:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1
hello world
^
SyntaxError: unexpected EOF while parsing
This is because the string is placed directly where input() was in the code. The user could surround his string with quotes in order to make this work, but you should never leave technical issues for the user to handle. There is a better way to write this code.
x = raw_input() #User types: hello world print x
'hello world'
>>> value = raw_input("Enter a positive integer: ")
Enter a positive integer: 5
>>> value * 2
'55'
>>> value
'5'
>>> value = int(value)
>>> value
5
>>> value * 2
10
>>>