| Assigned | Wednesday, Oct 15, 2008 |
| Due | Thursday, Oct 30, 2008 at 11:59 PM |
| Updates |
Another application near and dear to the hearts of Computer Science teachers and students is figuring out whether students have copied code from each other. For example, if you see two project submissions that both have this code, you can be pretty sure they are cheating:
for (int abc123 = 0; abc123 < 100 - 10; abc123 = abc123 + 2 - 1)
System.out.println(abc123);
Why? Because those two are probably the only projects that contain
the strings "abc123" and "< 100 - 10" and "+ 2 - 1".
In this project, you will implement a program that checks for cheating using a data structure called a trie.
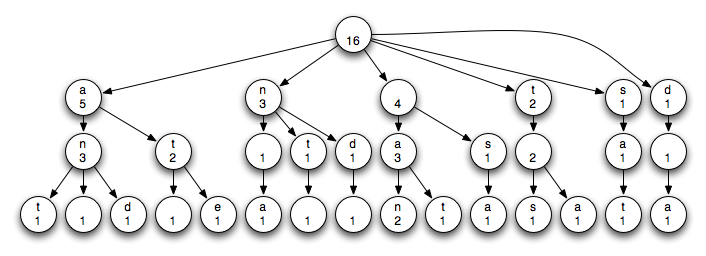
Consider the following input text:
'an ant sat and ate'Suppose the depth bound is 3. To build the trie you'll take a window of width 3 and pass it over the input text file, yielding the following substrings:
'an ' 'n a' ' an' 'ant' 'nt ' 't s' ' sa' 'sat' 'at ' 't a' ' an' 'and' 'nd ' 'd a' ' at' 'ate'
You then build a tree such that there is a path from the root for each of these substrings, and keep counts for each node of the number of substrings that have passed though it. The final trie looks like this:
Each trie node contains a character and a count. There are 16 substrings of length 3, so the root was visited 16 times. The root node is the only node for which the character data member is ignored. Of the 16 substrings, 5 started with the letter 'a', so the (leftmost) child of the root labeled 'a' has a count of 5. The 5 substrings that started with 'a' are:
'an ' 'ant' 'at ' 'and' 'ate'The initial 'a' is followed by either an 'n' (in 'an ', 'ant', and 'and') or a 't' (in 'at ' and 'ate'), so that node has two children labeled 'n' and 't'. Note that substrings that share a common prefix (as 'and' and 'ant' share the two-character prefix 'an') share tree structure.
Suppose your program is run with this command line:
java Proj3 3 2 file1.txt file2.txtSuppose the 2 most frequent 3-letter sequences in file1.txt are "and" and "the", and that they occurred 57 and 45 times, respectively. Forthermore, suppose those sequences occurred in file2.txt 100 and 94 times, respectively. Your output might look like this:
Sequence # in file1.txt # in file2.txt -------- -------------- -------------- and 57 100 the 45 94
The list of strings should be sorted in descending order according to their frequency in the first text file. If there are strings that have the same frequency as the Nth string in the list, print all of them along with their frequencies in both files. In the example above, if the string "was" occurred 45 times in file1.txt, but the next most frequent string occurred 39 times, the output should look like this (assuming "was" occurred 52 times in file2.txt:
Sequence # in file1.txt # in file2.txt -------- -------------- -------------- and 57 100 the 45 94 was 45 52
Requirements
public class Trie< T > { ... }
Note that it must be possible to test objects of type T for
equality (e.g., via the equals method).
Trie< Character > trie = new Trie< Character >();
String text = new String("an ant sat and ate");
Vector< Character >> sequence = new Vector< Character >>();
for (int i = 0; i < 4; i++)
sequence.add(text.charAt(i));
trie.addSequence(sequence);
Hints
public void remove() {
throw new UnsupportedOperationException();
}
ant ant doc ant -Dargs="3 2 file1.txt file2.txt" run
See the projects page for more information on all of these topics.
If you don't submit a project correctly, you will not get credit for it. Why throw away all that hard work you did to write the project? Check your submittals. Make sure they work. Do this before the due date.
Project grading is described in the
Project
Policy handout.
Cheating in any form will not be tolerated. Please re-read the Project
Policy handout for further details on honesty in doing projects for this
course.
Remember, the due date is firm. Submittals made after midnight of the due date will not be accepted. Do not submit any files after that time.