| Assigned | 29 Nov 2004 |
| Due | 12 Dec 2004 at 11:59PM |
This is the fifth and final project this semester. At this point in your education, you should be able to go from a description of desired functionality in prose to the technical details, including class definitions and program design. Therefore, this assignment is intentionally less detailed than some of the earlier ones. Be sure to get started early to ensure that you have enough time to think through the design and to ask questions as they arise.
The standard priority queue implementation based on a binary heap does not make it possible to efficiently change the priority of an entry. In the worst case, doing so would require a linear search of the underlying array of items to find the one whose priority is to be changed. In this assignment, you will implement a data structure known as a Hashed Priority Queue (HPQ) that supports efficient, dynamic changes to priorities.
Here are your tasks:
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/Proj5/
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/Proj5/341-Fall04-p5_questions.txt
to your own directory and edit it to provide your answers to the questions. Don't forget to submit the edited file; it's 10% of this project's grade.
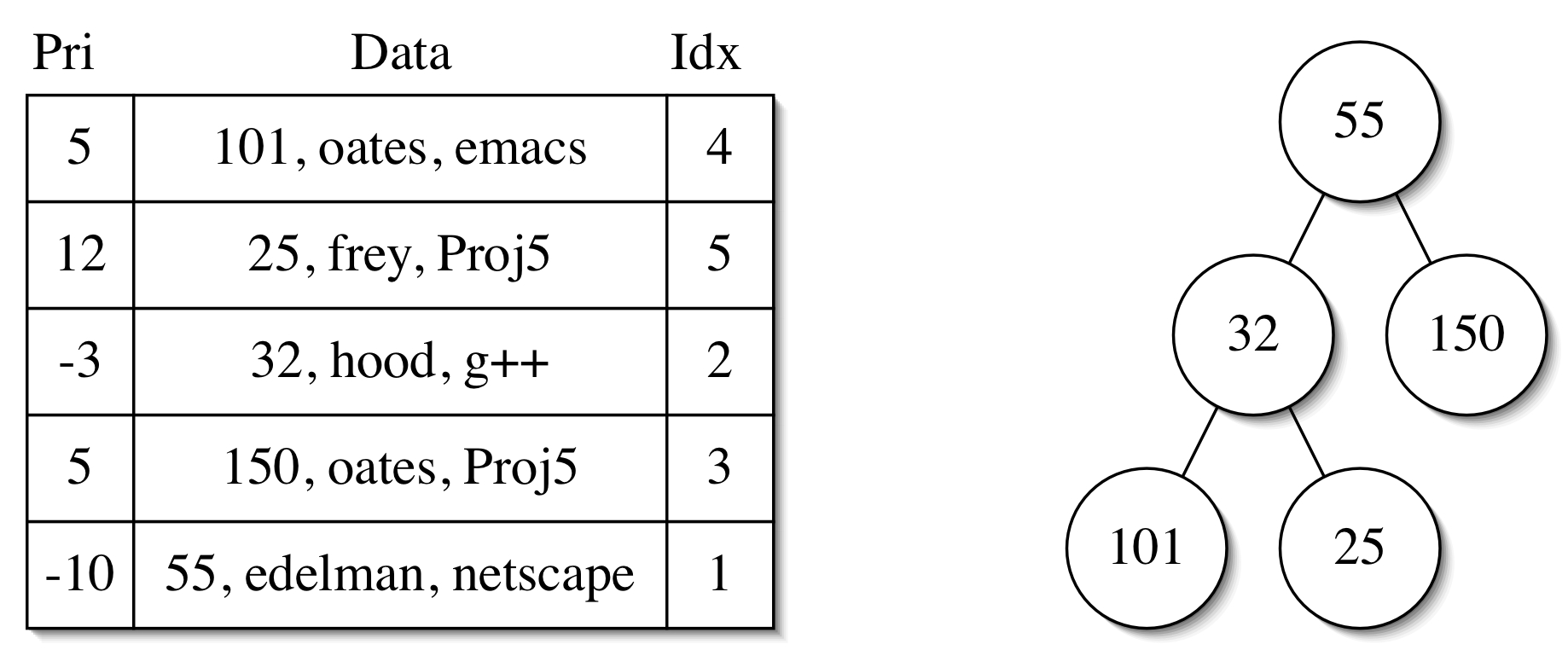
Now consider the binary heap on the right-hand side of the figure. Each node contains the PID of a process stored in the hash table. For example, the root of the binary heap contains the PID 55. All of the information about process 55 can be obtained by performing a find on the hash table with 55 as the key. Therefore, to go from a node in the binary heap to the corresponding data requires constant time. The entries in the binary heap are ordered by the priorities of the corresponding processes, not the PIDs stored in the binary heap nodes. The PIDs serve as unique identifiers that make it possible to obtain the corresponding data from the hash table
Given the PID of a process, it is possible to find the corresponding node in the binary heap via the Idx field of the data stored in the hash table. Recall that the nodes in a binary heap are stored in an array in level order. The process with PID 32 has Idx 2, and that PID is found in the second node in the binary heap in level order, which is at array position 2. Likewise, the process with PID 101 has Idx 4, and that PID is found in the fourth node in the binary heap in level order, which is at array position 4. Therefore, to go from a PID to a node in the binary heap requires constant time (one find on the hash table with the PID to retrieve the Idx, and one array dereference to get the node in the binary heap).
Your implementation of the HPQ must be templated. For this project, you will want to define a class such as ProcessInfo that stores information about Unix processes. Your main routine might then have the following declaration:
HashedPriorityQueue<ProcessInfo> HPQ;Note, however, that any class used as a template parameter when declaring an HPQ must have data members that can serve as a hash key and a priority. When writing your code, you can assume that both of these data members will be integers and that the hash keys are all positive. You will also need to assume that the class implements the following methods:
You will need to modify the binary heap code in two ways. First, in a standard binary heap, elements are ordered based on their own value (via operator<). In an HPQ elements in the heap are ordered based on the priority of the corresponding objects in the hash table. Second, it must be possible (see the command file section below) to change the priority of an element in the heap given its hash key. To do this, you will use the hash key to find the data item in the hash table, change its priority, then use the Idx field to find the corresponding node in the binary heap, and percolate up or down as needed to restore the heap order property. Any time elements are moved in the heap, you must be sure to update the corresponding Idx fields in the hash table.
Note that you must check command line arguments to ensure that they
are valid, e.g. that the command file can be opened, and print an
appropriate message if an error is found.
Echo each command as it is read.
The command file format follows:
Submit the files using the procedure given to you for your section of
the course.
If your makefile is set up correctly, you should be able to execute
the command make submit.
If you don't submit a project correctly, you will not get credit
for it. Why throw away all that hard work you did to write the project?
Check your
submittals. Make sure they work. Do this before the due date.
Documentation for the submit program is on the web at http://www.gl.umbc.edu/submit/.
One of the tools provided by the submit program is
submitls. It lists the names of the files you have submitted.
Additionally, there are two programs for use only by CMSC-341 students
(not part of the UCS submit program). They are in the directory
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/ and are
named submitmake and submitrun. You can
use these programs to
make or run your submitted projects.
The syntax is similar to that for submit:
submitmake <class> <project>
Example: submitmake cs341 Proj4
This makes the project, and shows you the report from the make utility.
It cleans up the directory after making the project (removes .o and ii_files),
but leaves the
executable in place.
submitrun <class> <project> [command-line args]
Example: submitrun cs341Proj1 checkers checkfile.dat
This runs the project, assuming there is an executable (i.e. submitmake
was run successfully).
Project grading is described in the Project Policy handout.
Your answers to 341-Fall04-proj1_questions.txt are worth 10% of your project grade.
Cheating in any form will not be tolerated. Please re-read the Project Policy handout for further details on honesty in doing projects for this course.
Remember, the due date is firm. Submittals made after midnight of the
due date will not be accepted. Do not submit any files after that time.