| Assigned | 1 Oct 2003 |
| Due | 14 Oct 2003 |
There are two main differences between a Jump List and a linked list. First, elements in a Jump List are always kept in sorted order. For example, if you insert the integers 10, 5, 11, and 8 into a Jump List in that order, the resulting list will contain <5, 8, 10, 11>. The second difference, and the one that is responsible for the better empirical performance of Jump Lists, is that each Jump List node contains both a pointer to the next node in the list and a pointer to the node K positions ahead of the node in the list, where K is a parameter. Therefore, it is possible to start at the head of the list and take steps of length K in addition to steps of length 1 when traversing the list.
You will modify the linked list code provided with the text to create a Jump List class, and measure the amount of work performed by the Jump List class for various values of K.
Here are your tasks:
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/Proj2/
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/Proj2/341-Fall03-p2_questions.txt
to your own directory and edit it to provide your answers to the questions. Don't forget to submit the edited file; it's 10% of this project's grade.
Note that the distance spanned by a jump pointer can change as elements are added to and removed from the list. For example, suppose the node containing the value 10 has a jump pointer that points to a node containing the value 30, and that 10 and 30 are K nodes apart. If the value 15 is inserted into the list, it will lie somewhere between 10 and 30, so the jump pointer from 10 to 30 now points K + 1 nodes ahead. That's OK. You do not need to ensure that all jump pointers always skip K nodes. Only when they are first inserted should this hold (if there are K or more nodes ahead of the inserted node).
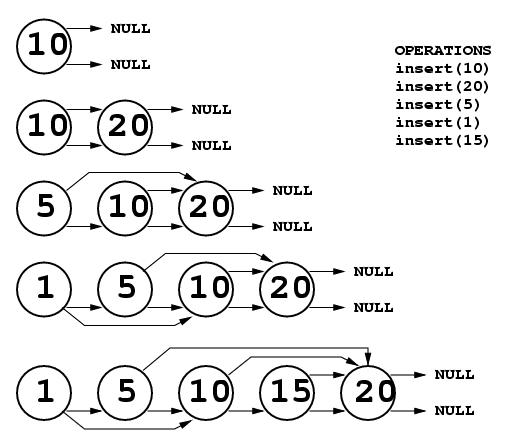
Below is an example of insertion into a Jump List with K = 2. In the figure, each node has two pointers. The upper one is the jump pointer and the lower one is the next pointer. First, the number 10 is inserted. Because it is the only element in the list, it's next pointer is NULL, and because there is no node 2 steps ahead of it in the list, the jump pointer is set to the value of the next pointer (i.e., NULL). Next, 20 is inserted. When inserting at the end of the list, the jump pointer of the previous node must be changed from NULL to point to the new node, just like the next pointer is updated. Next 5 is inserted, and there is a node 2 steps ahead so the jump pointer points to 20. Next 1 is inserted, and it's jump pointer points to 10. Finally, 15 is inserted. There is no node 2 steps ahead of it, so the next and jump pointers both point to the same node. Note that the jump pointer for the node containing 5 now points 3 nodes ahead. That is as it should be. Once jump pointers are set, they never change unless a node is deleted or a new node is inserted at the end of the list (as in the example above).
Finding an object in a Jump List is very different from finding an object in a linked list. First, the values are in sorted order, so you only need to scan the list until you either find the object or find an object whose value is greater than the target. For example, when searching for the value 6 in the list <3, 5, 7, 10, 20> the search can stop when the node containing 7 is discovered, because all values after that one will be larger than 6.
Second, Jump Lists make it possible to take steps of size K rather than size 1 through the list. When searching for object X in a jump list, you follow jump pointers until you fall off the end of the list, find the object, or come to an object that is greater than X. In the first two cases, you're done. In the last case, it may be that you jumped over the object you're seeking. Therefore, you need to back up to the node that caused you to jump to the current location and follow next pointers, not jump pointers. Now if you come to a node whose value is greater than the target you know the target does not exist in the list. All routines that search for a value in a list, such as find, must use this approach.
To make this clear, consider the following list:
3, 6, 9, 10, 11, 20, 32, 35, 36, 40, 41
Suppose this list was created with K=3. A search for the value 20 would start at the first node in the list, whose value is 3. This is not the target value, so the jump pointer is followed, which points 3 nodes ahead to the node containing the value 10. This is not the target, so again a jump pointer is followed to the node containing the value 32. This is larger than the target, so the search returns to the node containing 10 and follows next pointers. This leads to the node containing 11 and then the node containing 20.
In the above example, if the target was 21 instead of 20, the results would have been the same, except when the node containing 20 was reached a next pointer would be followed to the node containing 32. At this point the search would be abandoned.
Below are some things to keep in mind when implementing your Jump List class:
This can be accomplished by creating a private Jump List data member called, say, num_comparisons, that the constructor sets to 0. Each time a routine like find or insert or remove compares X to a list node's element, increment num_comparisons. For example, the author's find routine for the list class contains the following code:
while( itr != NULL && itr->element != x )
itr = itr->next;
You would need to modify it as follows:
while( itr != NULL && itr->element != x ) {
itr = itr->next;
num_comparisons++;
}
As your program processes a command file, after every 100 commands it must
print the total number of comparisons performed thus far and the average
number of comparisons per command processed from the file. The questions
for this project will ask you to discuss the impact of varying K on
performance.
Note that you must check command line arguments to ensure that they are
valid, e.g. that the command file can be opened, and print an appropriate
message if an error is found.
The command file format follows:
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/Proj2/341-Fall03-p2-sample_output.txt
Note that this output was NOT created by executing any program,
but generated artificially by hand.
If you don't submit a project correctly, you will not get credit
for it. Why throw away all that hard work you did to write the project?
Check your
submittals. Make sure they work. Do this before the due date.
Documentation for the submit program is on the web at http://www.gl.umbc.edu/submit/.
One of the tools provided by the submit program is
submitls. It lists the names of the files you have submitted.
Additionally, there are two programs for use only by CMSC-341 students
(not part of the UCS submit program). They are in the directory
/afs/umbc.edu/users/o/a/oates/pub/CMSC341/ and are
named submitmake and submitrun. You can
use these programs to
make or run your submitted projects.
The syntax is similar to that for submit:
submitmake <class> <project>
Example: submitmake cs341 Proj2
This makes the project, and shows you the report from the make utility.
It cleans up the directory after making the project (removes .o and ii_files),
but leaves the
executable in place.
submitrun <class> <project> [command-line args]
Example: submitrun cs341Proj2 checkers checkfile.dat
This runs the project, assuming there is an executable (i.e. submitmake
was run successfully).
Project grading is described in the Project Policy handout.
Your answers to 341-Fall03-proj2_questions.txt are worth 10% of your project grade.
Cheating in any form will not be tolerated. Please re-read the Project Policy handout for further details on honesty in doing projects for this course.
Remember, the due date is firm. Submittals made after midnight of the
due date will not be accepted. Do not submit any files after that time.