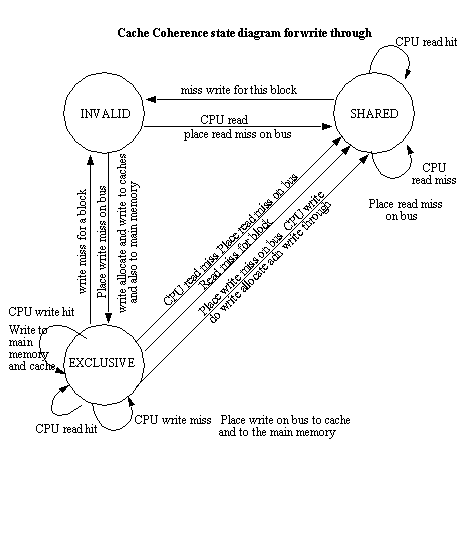
Problem 1
From the point of view of the implementator, the major hardware
functionality that is not needed with a write-through cache compared with
a write back cache is: When the block is exclusive, local cpu read miss
and write miss, or read miss and write miss message from bus occurs, the
cache doesn t have to write back the block to memory.
Problem 2
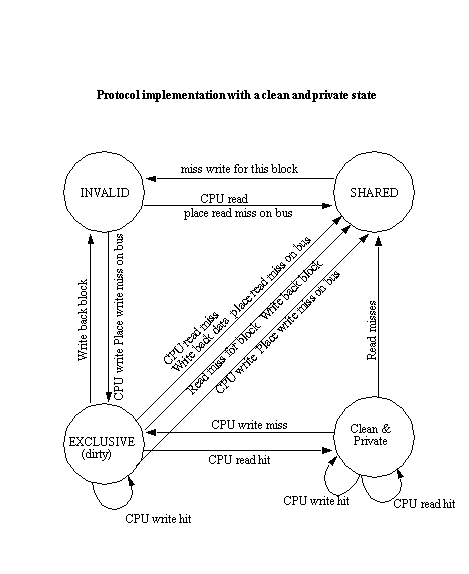
Problem 3
If a valid bit is added to each word in a block, there would be extra
complications to the basic snooping cache coherency protocol to allow invalidation
a word without removing the entire block. When the state is invalid, then
CPU reads, it has to check the valid bit of the words it wants to read,
if valid, it won t generate a read miss, or it places read miss on bus.
On write, besides place write miss on bus, it has to provide the information
about the words it tries towrite. When the state is shared, if it gets
write miss for block from bus, it should invalidate the words others write
when it changes into invalid state.
And when CPU writes, it also should provide information about the words
it writes to let others invalidate such words. When the state is exclusive,
when it gets write miss for block from bus, it should set the valid bits
of the words others write invalid when the state is changed into invalid.
The logic for checking bits when read and invalidate, and for providing
information about the words would be more complicated.
Problem 4
(a) The miss time for Challenge as given in the book
is 1093 ns
On the DSM a local access will take;
Miss time = Cache miss + Memory access + reload cache line latency+
reload primary cache latency
= ( ( 40 + (16 * 3) + 10) * 6.67 ns ) + 150 ns = 803.66 ns.
Therefore the DSM is better than the Challenge by:
(1093 - 803.66) / 1093 = 26.47%
(b) For the Challenge the average memory
access time is:-
22 bus cycles * 20 ns = 440 ns.
For the DSM grid the average distance from one node to the other is 2.8 cycles. All the 16 nodes have been taken in account for this average calculation.
With the hop being only 1 the average memory access time will be :
CCT * ( start latency + 2 * average distance) + memory latency
= ( 10 * ( 5 + 5.6 cycles)) + 150 ns = 256 ns.
The DSM grid is faster than challenge by :
(440 - 256) / 256 = 71.875%
Let n be the number of hops required to access the memory where the data
is stored. To make the DSM perform better than the Challenge
we require that
CCT * (start latency + 2 * average distance) + 150 ns = 440.
10 * ( 5 + 5.6 n) + 150 =440
Therefore n = 4.29
Therefore the fraction of remote misses for which the DSM performs better
than Challenge will be:
(number of hops - 1) / 6
= (4.29 -1) / 6
= 54.8%
Problem 5
We know that DSM and COMA machine have same remote coherence misses, but different local memory miss. So, to get equal performance, we have to get the same local miss rate, that is: ( x = fraction of the capacity miss on the DSM machine).
40*x + (1-x) *75 = 50
x = 71.42 %