In this homework assignment you will gain familiarity with WEKA, the Waikato Environment for Knowledge Analysis. WEKA is widely used in the machine learning and data mining communities because, among other things, it provides both a nice user interface to a number of standard algorithms and a Java API. You will also solidify what you learned about decision trees and nearest neighbor classifiers in class by experimenting with them on real and artificial data.
Each instance should consist of some number of binary attributes, whose values are assigned at random, and a binary class label, whose value is determined by a boolean function of your choice and is corrupted by noise with some probability. Your program should take at least the following parameters:
What to submit: Write a couple of paragraphs describing some of the structure you found in the dataset.
What to submit: Submit the output of the classifier on your dataset and describe, in words, what structure the decision tree found in the data.
Using your data generator, explore the impact of dataset size, number of irrelevant attributes, and noise on the ability of J48 to learn a good decision tree. Try to find a dataset for which the decision tree perfectly captures the function you used to assign class labels.
What to submit: Write a few paragraphs summarizing your observations on how features of the dataset impact the learned decision trees and, in particular, whether or not the trees are overfit. Submit the "best" decision tree you were able to obtain using J48.
What to submit: Write a couple of paragraphs summarizing your observations on how features of the dataset impact accuracy of the IB1 classifier. Also compare/contrast the performance of IB1 and J48.
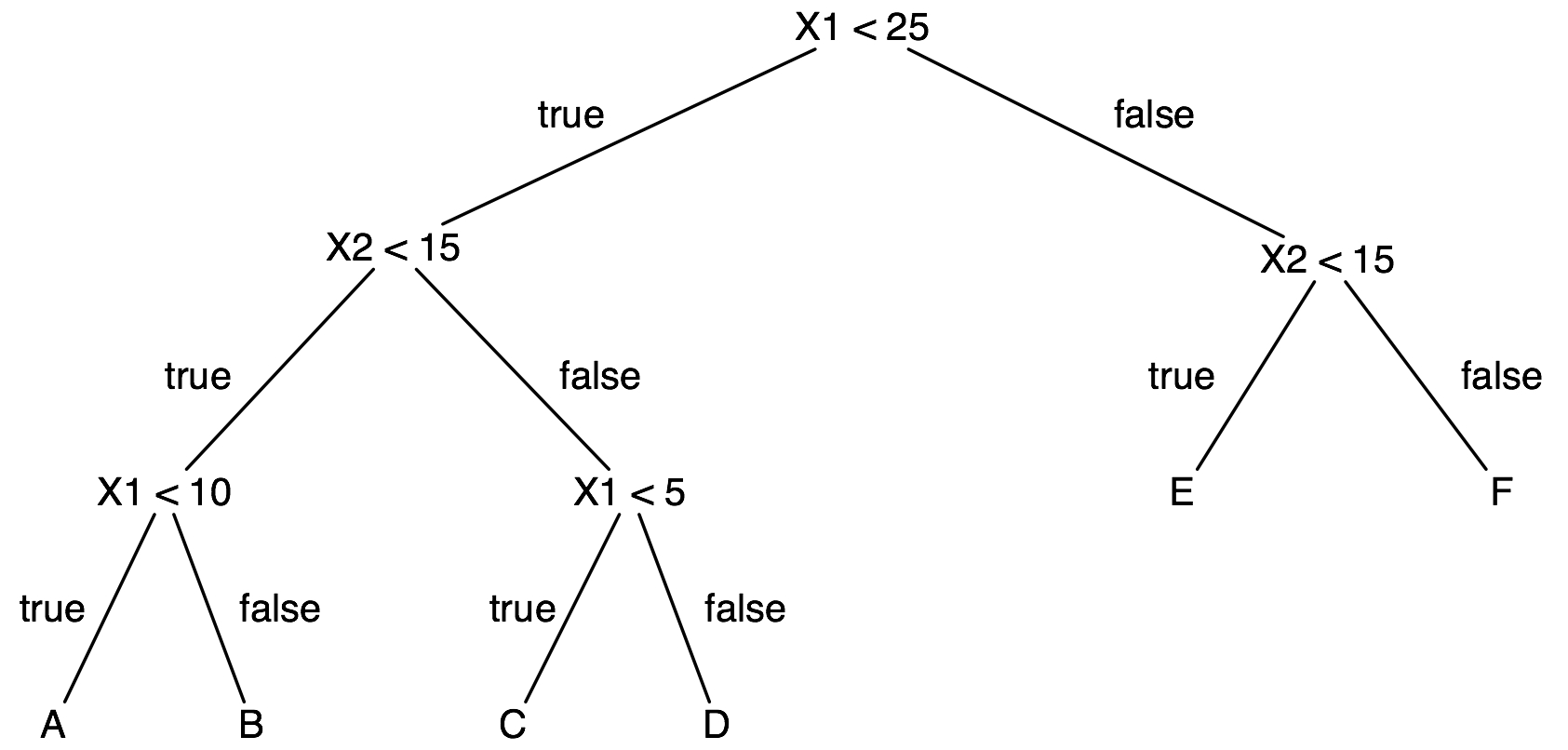
(A) Draw the decision boundaries defined by this tree. That is, draw in the plane defined by X1 and X2 the rectangular regions corresponding to the subset of the instance space covered by each leaf. Each leaf is labeled with a letter. Write this letter in the corresponding region of instance space.
(B) Give another decision tree that is syntactically different but defines the same decision boundaries. This demonstrates that the space of decision trees is syntactically redundant.

(A) Draw the decision boundary for the 1-nearest neighbor algorithm assuming that we are using standard Euclidean distance to compute nearest neighbors.
(B) How will the point (8, 1) be classified?
(C) How will the point (8, 8) be classified?
This problem is famous for confounding lots of very smart people who say that it makes absolutely no difference whether you switch or not. The reasoning is that opening a door with a goat doesn't change the probability that the car is behind the door you initially chose. It's still 1/3.
It turns out that it is best to switch!
Your assignment is to present a Bayesian argument as to why this is the case. Feel free to use external resources (like the web), but I want you to submit a short writeup based on the application of Bayes rule that is entirely your own. Read and understand the arguments, but write them up in your own words.