II. SVMs and Kernel Spaces (25 pts)
I'm looking for a paragraph or so on each of these questions, not a lengthy exposition on every aspect of the methods.- Linear Models (8 pts) Linear SVMs and decision trees both learn linear separators in the instance space. Do they therefore have the same model space? If so, explain why these two approaches differ in the way they search the model space. If not, explain what the main differences are between the two model spaces.
- Kernel Basis Functions (8 pts) What are kernel basis functions used for in SVM learning? How do they change the model space of the learner?
- Basis Functions and Decision Trees (9 pts) Supppose that one incorporated a set of kernel basis functions -- say, low-order polynomials -- into the feature space for a decision tree. Would the model space then look the same as that of an SVM in that kernel space? Why or why not?
III. MDPs and RL (25 pts)
The diagram below shows a gridworld domain in which the agent starts at the upper left location. The upper and lower rows are both "one-way streets," since only the actions shown by arrows are available.
Actions that attempt to move the agent
into a wall (the outer borders, or the thick black wall
between all but the leftmost cell of the top and bottom
rows) leave the agent in the same state it was in with
probability 1, and have reward -2.
If the agent tries to move to the right from the upper right
or lower right locations, with probability 1,
it is teleported to the far left end
of the corresponding row, with reward as marked.
All other actions have
the expected effect (move up, down, left, or right)
with probability .9, and leave the agent in the same state it was
in with probability .1. These actions all have utility -1,
except for the transitions that are marked. (Note that the
marked transitions only give the indicated reward if the action
succeeds in moving the agent in that direction.)
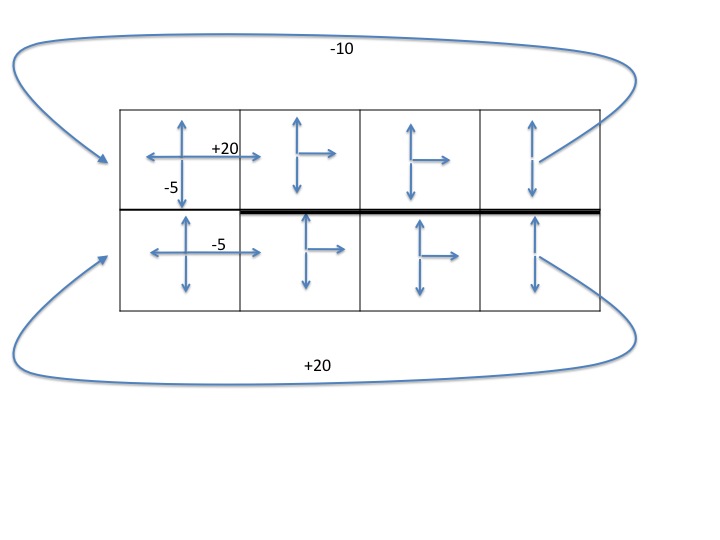
(a) MDP (10 pts) Give the MDP for this domain
only for the state transitions starting from each of
the states in the top row, by filling in a
state-action-state
transition table (showing only the state transitions
with non-zero probability). You should refer to each state
by its row and column index, so the upper left state is [1,1]
and the lower right state is [2,4].
To get you started, here are the first few lines of the table:
| State s | Action a | New state s' | p(s'|s,a) | r(s,a,s') |
| [1,1] | Up | [1,1] | 1.0 | -2 |
| [1,1] | Right | [1,1] | 0.1 | -1 |
| [1,1] | Right | [1,2] | 0.9 | +20 |
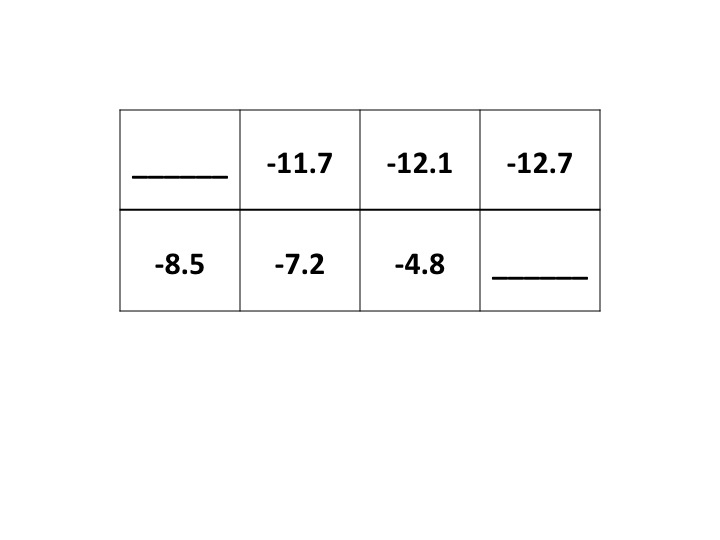
(b) Value function (8 pts)
Suppose the agent follows a randomized policy π (where each
available action in any given state has equal probability)
and uses a discount factor of γ=.85.
Given the partial value function (Vπ; Uπ in
Russell & Norvig's terminology) shown below,
fill in the missing Vπ values. Show and explain your work.
(c) Policy (7 pts)
Given the value function Vπ computed in (b),
what new policy π' would policy iteration produce at
the next iteration? Show your answer as a diagram (arrows
on the grid) or as a state-action table.